글을 시작하기 전에 별로 중요하지 않다 생각하고 넘긴 CLR에 대해서 알아보겠다
CLR(Common Language Runtime) : C#으로 만든 프로그램이 실행되는 환경
C#뿐만 아니라 LS 규격을 따르는 모든 언어로 작성된 프로그램을 지원해준다
다른 언어로 작성된 언어 사이의 호환성을 제공해주기도 한다. "C# 프로그램을 실행해주는 또 다른 프로그램" 정도로 알고 있자
-------------------------------------------
컴퓨터가 무엇을 하느냐는 소프트웨어가 결정한다. 그리고 그 소프트웨어는 우리가 만든다
그렇기에 소프트웨어가 다뤄야 할 수많은 데이터는 우리가 관리해야한다
그리고 C#은 우리의 임무를 돕기 위해 다양한 종류의 데이터 형식을 제공한다
이번엔 그 데이터 형식. 정확히는 기본 데이터 형식과 상수, 그리고 열거형을 배워보도록 하자
그전에 먼저 변수라는 개념부터 짚고 넘어가겠다
<변수>
데이터를 담는 일정 크기의 공간
변수를 만드려면 변수가 할당받을 메모리 공간도 생각해야 한다
우리는 변수를 선언한다(Declare)라고 하는데
변수를 선언한다 = 컴파일러에게 "이 변수에 필요한 메모리 공간을 예약해줘"와 같은말
int a;
데이터 형식을 쓰고 변수의 이름을 명시. 그리고 끝에 세미콜론을 붙여 컴파일러에게 알려준다
이렇게 되면 컴파일러는 int 타입을 위해 메모리 공간을 할당하고 이 공간에 a라는 식별자가 사용할 수 있도록 준비한다
a = 100;
a를 위해 할당된 메모리 공간안에 데이터 100이 기록된다
*초기화 : 변수에 최초의 데이터 할당을 해주는것.
C++은 초기화를 해주지 않으면 변수안에 쓰레기값이 들어가 오류를 냈지만 C#은 애초에 실행파일을 만들어주지 않는다
int a = 100;
int a,b,c;
int a = 30, b = 20, c = 10;
선언하자마자 값 할당, 동시에 여러개 선언, 값할당 모두 가능하다
-----------------------------------------
자 그럼 이제 값 형식과 참조 형식에 대해서 알아보자
값 형식 : 변수가 값을 담는 데이터 형식
참조 형식 : 변수가 값 대신 값이 있는 곳(참조)의 위치를 담는 데이터 형식
이 둘을 더 정확히 이해하려면 두 가지 메모리 영역에 대해 알고 있어야한다
그것이 바로 스택과 힙이다
이 두 메모리 영역중 값 형식과 관련이 있는건 스택 메모리 영역
참조 형식과 관련이 있는것은 힙 메모리 영역이다
<스택 메모리>
{
int a = 1;
int b = 2;
int c = 3;
}

아주 간단하다 위처럼 코드를 썻다고 가정하면
코드블럭의 시작 { 중괄호가 실행되는 시점에는 empty stack 상태이다
그러나 int a = 1;을 실행하는 순간 변수 a가 스택에 쌓이게 된다
차례대로 들어오고 나갈때는 c>b>a순으로 나가는 형식이다
그리고 마지막 닫는 } 중괄호를 만나는 순간 코드블록에서 생성된 모든 값 형식의 변수들은 메모리에서 제거된다
쉽게 말해 스택 메모리 구조는 끝나는 순간 안에 있던 모든 메모리들을 제거하는 메커니즘이 있다
하지만 힙 메모리 구조는 그렇지 않다. 자동으로 제거하지 않고 CLR의 가비지 컬렉터라는 청소부가
더이상 힙에 사용하지 않는 객체가 있다면 쓰레기로 간주하고 제거해준다
그럼 왜 굳이 스택을 냅두고 힙 메모리를 쓰는것일까? 상황에 따라 제거하고 싶지 않은 데이터도 있을 수 있기 때문
만약 프로그래머가 힙에 데이터를 올려놓으면 코드의 종료와 상관없이 데이터를 살려준다
참조 형식의 변수는 힙과 스택을 함께 사용하는데

{
object a = 10;
object b = 20;
}
이렇게 보면 이해가 빠를것이다
실제값 10,20은 힙에 저장하고 a와 b는 값이 저장된 힙의 주소만 스택에 저장해둔다
위에 적은대로 스택의 특성상 코드가 끝나면 스택에 있는 데이터들은 자동 삭제되지만
그건 어디까지나 힙의 주소일뿐, 실제값인 10,20에는 아무런 지장이 없다
그럼 힙의 10,20은 언제 지워지느냐? 이 데이터를 참조해주는 곳이 없을때 가비지 컬렉터가 와서 청소를 해주게 된다
------------------
<데이터 형식>

데이터 타입이다. 다른건 별다른 설명이 필요없겠지만 "부호 없는/있는 정수"만 짚고 넘어가자
부호라고 한다면 +,-를 의미하고 음수의 경우 무조건 수 앞에 -를 붙여줘야한다.
부호가 없다면 무조건 양의 정수로 간주하기 때문
그렇다면 부호 없는 정수란? 말 그대로 음수없이 무조건 양의 정수만 취급한다는 의미이다.
잘보면 부호있는정수 sbyte는 -128 ~ 127까지 다루지만
그냥 정수 byte는 0 ~ 255까지 다룰수 있다. 왜 범위가 두배가 되는걸까?
2진수의 부호를 나타내는 비트를 쓸일이 없어 하나의 비트를 더 사용가능해지기 때문이다
그리고 저 표에 적히진 않았지만 한가지가 더 있으니 그건 바로 "object"이다
상속 효과 덕분에 모든 부모 데이터 형식을 전부 물려받은 object는 모든 데이터 형식을 다 받아낼 수 있다
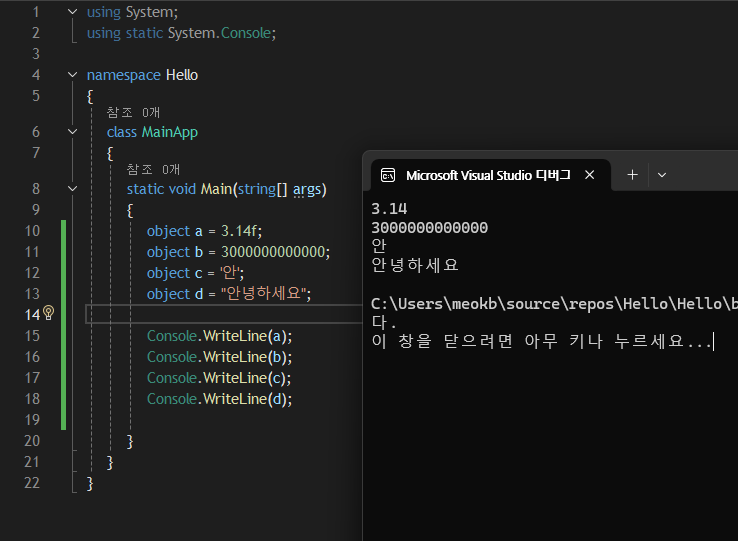
전부 수용이 가능한것을 확인할 수 있다
<박싱, 언박싱>
그럼 이렇게 생각할 수 있다
object a = 20;
스택에는 a, 힙에는 20이 들어갈텐데 이 object가 무슨 타입인줄 알고 힙에 20을 집어넣을까.
그래서 "박싱"이라는 기능을 제공한다. 말그대로 20이라는 값을 박스에 포장한것
그럼 이 박스에 포장된 20이라는 값을 다시 꺼내는데 만약 int 타입으로 꺼내고 싶다면 어떻게 해야할까
object a = 20;
int b = (int)a;
이렇게 박싱된 값을 꺼내 값 형식 변수에 저장하는 과정을 언박싱이라고 한다

<형식 변환>
변수를 다른 데이터 형식의 변수에 옮겨 닮는것을 "형식 변환" 이라고 한다
형식 변환 역시 언박싱과 같은 형태이다
float a = 0.1;
double b = (double)a;
a : 0.1
b : 0.100000000014911612
이렇게 출력이 되는것을 확인할 수 있다
b는 a의 값을 그대로 형변환을 하여 가져왔지만 단위가 달라지며 미세한 차이가 났기 때문에
둘은 같은 숫자로 간주하지 않는다
int a = -30;
uint b = (uint)a;
a : -30
b :4294967266
부호가 있는 int 타입을 부호없는 uint타입으로 변환하면 언더플로우가 일어나게 된다
float a = 0.9;
int b = (int)a;
a : 0.9
b : 0
이런 경우에는 소수점 밑자리를 버리고 정수부분만 남긴다. 반올림 없음
string a = "12345"
int b = (int)a;
int c = 12345;
string d = (string)c;
이 코드들은 아예 컴파일조차 되지않는다. 이런 변환 방법은 없기 때문
하지만 숫자 - 문자를 서로 변환할 수 있는 방법이 있다.
(문자 => 숫자)
int a = int.Parse("12345");
float b = float.parse("123.45");
이는 Parse()라는 메서드로 이 메서드에 숫자로 변환할 문자열을 넣어주면 숫자로 변환해준다
문자를 직접 입력받아 숫자로 변환하고 싶다면
int input = Convert.ToInt32(Console.ReadLine());
이것도 가능하다
(숫자 => 문자)
int a = 12345;
string b = a.ToString();
float c = 123.45;
strinf d = c.ToString();
이는 ToString() 메서드로 숫자를 문자열로 변환시켜준다.

'C# > 1. 데이터 보관과 가공 & 코드의 흐름제어' 카테고리의 다른 글
| 연산자(증가/감소연산자, 조건연산자), 반복문, 점프문 (3) | 2025.03.12 |
|---|---|
| 상수와 열거형식, Nullable, var, 문자열 다루기 (0) | 2025.03.11 |
| 객체지향 프로그래밍, .NET, (2) | 2025.03.03 |